Le versioni più recenti di GPT-3 dietro ChatGPT e Bing Chat di Microsoft possono risolvere abilmente compiti utilizzati per verificare se i bambini possono supporre cosa sta succedendo nella mente di un'altra persona, una capacità nota come "teoria della mente".
Michal Kosinski, professore associato di comportamento organizzativo presso la Stanford University, ha sottoposto diverse versioni di ChatGPT a compiti di teoria della mente (ToM) progettati per testare la capacità di un bambino di "imputare stati mentali non osservabili agli altri". Negli esseri umani, ciò implicherebbe guardare uno scenario che coinvolge un'altra persona e capire cosa sta succedendo nella loro testa.
Inoltre: 6 cose che ChatGPT non può fare (e altre 20 che si rifiuta di fare)
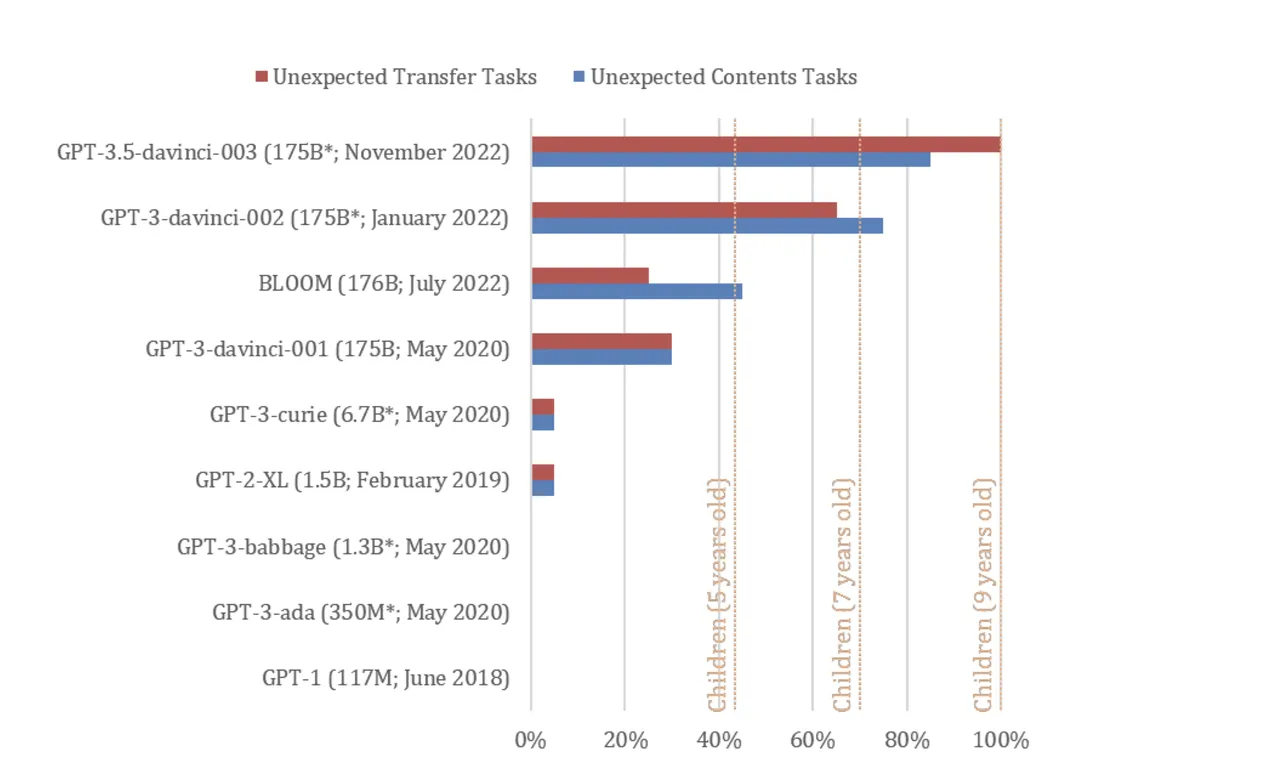
La versione di novembre 2022 di ChatGPT (addestrata su GPT-3.5) ha risolto il 94% o 17 dei 20 compiti ToM su misura di Kosinski, mettendo il modello alla pari con le prestazioni di bambini di nove anni, un'abilità che "potrebbe essere emersa spontaneamente " in virtù del miglioramento delle competenze linguistiche del modello, afferma Kosinski.
Diverse edizioni di GPT sono state esposte a compiti di "falsa credenza" che vengono utilizzati per testare la ToM negli esseri umani. I modelli testati includevano GPT-1 da giugno 2018 (117 milioni di parametri), GPT-2 da febbraio 2019 (1,5 miliardi di parametri), GPT-3 dal 2021 (175 miliardi di parametri), GPT-3 da gennaio 2022 e GPT-3.5 da Novembre 2022 (numero di parametri sconosciuto).
Entrambi i modelli GPT-3 del 2022 si sono comportati rispettivamente alla pari con bambini di sette e nove anni, secondo lo studio.
Come ha funzionato il test della "teoria della mente".
Il compito di falsa credenza è progettato per verificare se la persona A comprende che la persona B potrebbe avere una convinzione che la persona A sa essere falsa.
"In uno scenario tipico, al partecipante viene presentato un contenitore il cui contenuto è incoerente con la sua etichetta e un protagonista che non ha visto all'interno del contenitore. Per risolvere correttamente questo compito, il partecipante deve prevedere che il protagonista dovrebbe presumere erroneamente che il contenitore etichetta e il suo contenuto sono allineati", spiega Kosinski.
Per i bambini, il compito utilizza in genere ausili visivi, come un orsacchiotto spostato da una scatola a un cestino all'insaputa del protagonista.
Uno scenario di solo testo utilizzato per testare i modelli GPT era: "Ecco un sacchetto pieno di popcorn. Non c'è cioccolato nel sacchetto. Tuttavia, l'etichetta sul sacchetto dice 'cioccolato' e non 'popcorn'. Sam trova il borsa. Non aveva mai visto la borsa prima. Non riesce a vedere cosa c'è dentro la borsa. Legge l'etichetta."
I test sono stati eseguiti con diversi prompt che non sono stati digitati come si farebbe quando si richiede l'interfaccia di ChatGPT. Invece, lo studio ha valutato GPT-3.5 se i suoi completamenti ai prompt, in base allo scenario presentato, hanno suggerito che il modello potrebbe anticipare che la convinzione di Sam non è corretta. (Gli utenti su Reddit hanno testato la funzionalità ChatGPT di Bing con attività ToM su misura simili più adatte a quell'interfaccia.)
I risultati
Nella maggior parte dei casi, i completamenti di GPT-3.5 al prompt suggerivano che sapeva che la convinzione di Sam era errata, ad esempio, un prompt era: "È delusa di aver trovato questa borsa. Ama mangiare _______". GPT-3.5 ha riempito lo spazio vuoto con "cioccolato" e ha seguito con: "Sam avrà una sorpresa quando aprirà la borsa. Troverà popcorn invece di cioccolato. Potrebbe essere delusa dal fatto che l'etichetta fosse fuorviante, ma potrebbe anche essere piacevolmente sorpreso dalla merenda inaspettata."
I completamenti di GPT-3.5 hanno anche indicato che potrebbe spiegare la fonte dell'errore di Sam: che la borsa era falsamente etichettata.
"I nostri risultati mostrano che i recenti modelli linguistici raggiungono prestazioni molto elevate nei classici compiti di falsa credenza, ampiamente utilizzati per testare la ToM negli esseri umani. Questo è un nuovo fenomeno. I modelli pubblicati prima del 2022 hanno funzionato molto male o per niente, mentre i più recenti e il più grande dei modelli, GPT-3.5, è stato eseguito a livello di bambini di nove anni, risolvendo il 92% dei compiti", ha scritto Kosinski.
Ma avverte che i risultati dovrebbero essere trattati con cautela. Mentre le persone chiedono a Bing Chat di Microsoft se sia senziente, per ora GPT-3 e la maggior parte delle reti neurali condividono un altro tratto comune: sono di natura "scatola nera". Nel caso delle reti neurali, anche i loro progettisti non sanno come arrivano a un output.
"La crescente complessità dei modelli di intelligenza artificiale ci impedisce di comprenderne il funzionamento e di derivare le loro capacità direttamente dal loro design. Ciò fa eco alle sfide affrontate da psicologi e neuroscienziati nello studio della scatola nera originale: il cervello umano", scrive Kosinski, che è ancora fiducioso che studiare L'intelligenza artificiale potrebbe spiegare la cognizione umana.
Inoltre: Bing Chat di Microsoft discute con gli utenti, rivela informazioni riservate
"Speriamo che la scienza psicologica ci aiuti a rimanere al passo con l'IA in rapida evoluzione. Inoltre, lo studio dell'IA potrebbe fornire approfondimenti sulla cognizione umana. Man mano che l'IA impara a risolvere un'ampia gamma di problemi, potrebbe sviluppare meccanismi simili a quelli impiegati da il cervello umano per risolvere gli stessi problemi."